Accuracy, Precision, Recall, and F1-score: Visualise
These are called performance metrics for classification models. We can use these metrics to evaluate how well the model has classified the data. The better we understand performance metrics, the better we can interpret them.
Before going further in the blog, I recommend you to go through this video first to visualise what exactly precision and recall are.
https://www.youtube.com/watch?v=qWfzIYCvBqo
So let’s see the interpretation of these metrics, first, we understand by taking some examples and later we cover it mathematically.
For a better understanding, compare the example covered in this blog to apples and oranges. If you haven’t watched the video, it might be a bit tricky to understand.
Accuracy:
Accuracy is the fraction of predictions our model got right, mathematically, it’s a ratio between the number of correct predictions to the total number of predictions. It is useful when all the classes have equal importance, and that’s where its drawback comes in. Particularly, for imbalanced classification problems where one class dominates the other. Let’s see how?
Let’s suppose we have documents, categorized into the sport, health, and food. Total of 1000 documents of which 990 are for sports, 5 for health, and 5 for food. Here, we can see that we have classes imbalanced towards sports documents. Now one classification model that results in high accuracy predicts every document as a sport and this will give an accuracy of 99%. But this is wrong. Here, we need to evaluate the model using other metrics which are precision and recall.
Precision and Recall
Now, precision and recall are defined in terms of one class, oftentimes the positive or minority class. Considering a dataset where we have two classes, patients having heart disease(1) or not (0). In this scenario, we calculate precision and recall for patients having heart disease (one class).
The trained model gives the probability of whether a patient has heart disease or not based on some input feature. The probability ‘p’ can be set in such a way that if p > x ( some value between 0 and 1), then the model will declare the patient has heart disease and x is known as the threshold value.
Notation: red color dot shows the patient has heart disease and the green color shows a healthy heart and the size shows severity.
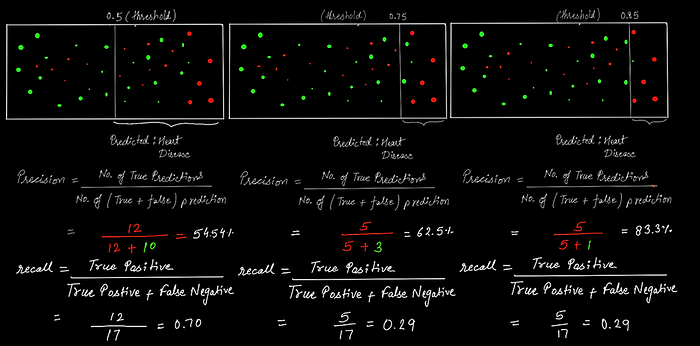
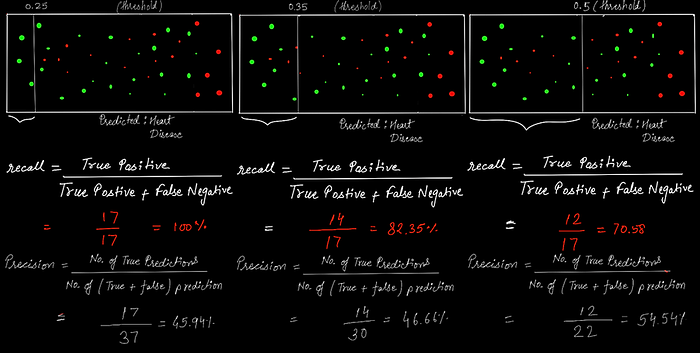
Figure (1) shows a threshold value of 0.5, which means that if the predicted value is greater than the threshold then the patient has heart disease, To understand precision and recall we are considering tow cases CASE 1: what if we want that model to detect only those patient which have severe heart disease? In this case, the threshold value will be increased to 0.75 (figure 2) or 0.85 (figure 3), a high threshold will classify heart disease only if the model is confident about its prediction. Hence, we can assert that increasing the threshold will increase precision.



Now, let’s see mathematically why precision is improving while increasing the threshold.

The definition of precision says “What proportion of identification is actually correct”. All the patients on the right side of the threshold value are classified as patients having heart disease and if there are patients with a healthy heart on the right side of the threshold then they will be misclassified (wrong prediction).
Precision is defined as:
Precision = (Heart Disease (Red Dots)) / ((Heart Disease (Red Dots)) + healthy heart (Green Dot))
OR
(True Positive (correct prediction)) / (True Positive (correct prediction) + false positive (wrong prediction))
We can see in the above images, precision is high for the last image because in this case, the classifier is more confident that the patient has heart disease. A precision score of 1.0 means that every heart classified as unhealthy is indeed unhealthy. (but says nothing about the number of unhealthy hearts which were misclassified).
Case 2: What if we want the model to detect all patients with heart disease? In this case, we have to shift the threshold line toward the left. And shifting the line to the left predicts a significant number of heart disease (true positive or red dots) cases. Thus, in this scenario, we are increasing the recall as more patients with heart diseases are detected by the model. Here, you can also notice that the precision will decrease as it will consider more false positives (i.e. will predict more healthy hearts as unhealthy, and precision gets low).
In some scenarios, it is required that the model detects all patients with heart disease, but there is no problem if the model predicts a healthy heart as unhealthy and in this, preference will be given to recall.
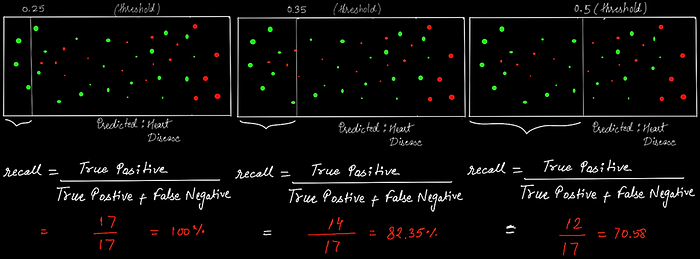
The definition of recall says “What proportion of actual positives was identified correctly?”, Here it means from all the patients having heart disease how much we have correctly classified. And that’s what the first image says, we have classified all the heart disease patients correctly and got 100% recall. But, again here you can’t say about the number of healthy hearts that are misclassified (As you can see all the green hearts are considered unhealthy in the first image. However, the model matches the requirement that patients with an unhealthy heart should not be predicted as healthy.). So, the recall is increased but the precision is decreased.
recall of 1.0 means that every item from the unhealthy heart class was labeled as belonging to the unhealthy heart class(but says nothing about how many items from healthy heart classes were incorrectly also labeled as unhealthy heart class).
In nutshell:
Precision: Of all positive predictions, how many are really positive?
Recall: Of all real positive cases, how many are predicted positive?
Precision and Recall: A Tug of War
To fully evaluate the effectiveness of a model, you must examine both precision and recall. Unfortunately, precision and recall are often in tension. That is, improving precision typically reduces recall and vice versa. This behavior is evident in the two images below. In the first, precision increases when recall decreases, and in the second, recall increases when precision decreases. But both have their own use cases, in CASE 1, we require high precision and in CASE 2, we require high recall. Accordingly, the precision and recall will be set, and this is a precision-recall trade-off (Increasing precision will decrease the recall, and vice versa).
Combining precision and recall: The F-measure
F-score is a way of combining the precision and recall of the model, and it is defined as the harmonic mean of the model’s precision and recall.
F-score formula:
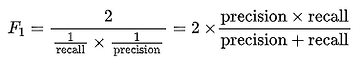
From the above image notice that the formula is taking both precision and recall into account. F1-score ranges between 0 and 1. The closer it is to 1, the better the model.
Hopefully, this blog helps you in understanding precision and recall.
Thanks.
